- Definition of xpath locator in Selenium webdriver
- xpath syntax/example
- Simplified xpath syntax
- xpath regular expression to identify element (‘contains’ keyword)
- Parent-child xpath relation
- Difference between relative and absolute xpath
- Source code
Definition of xpath locator in Selenium webdriver
We can identify elements using their xpath (which is simply an address of an element on the webpage). Xpath help us reaching a desired element on the web page.
xpath syntax/example
The xpath syntax: //tagname[@attribute=’value’]
xpath example: //input[@name=’Submit’]
In the above example, we are trying to find an element that has the tag name “input” & the value of its “name” attribute is ‘Submit’.
Let us see a practical example.
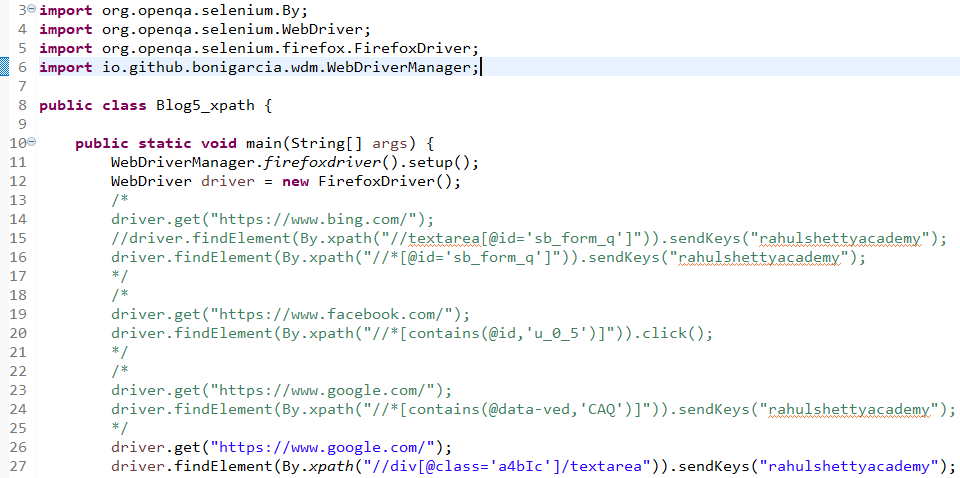
Launch https://www.bing.com/ and inspect the search text field.
Notice below that the search field is represented by tagname ‘textarea’, attribute ‘id’ and the attribute’s value is ‘sb_form_q’
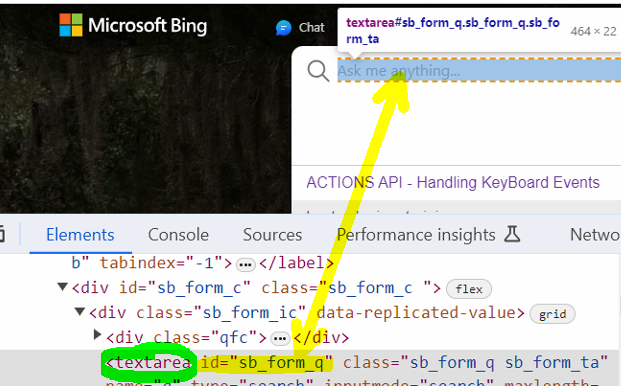
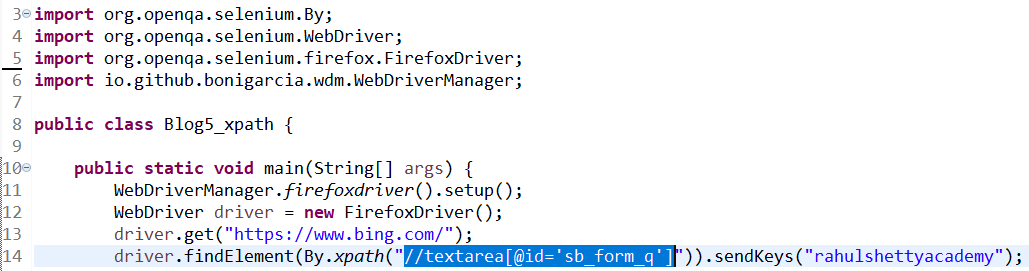
Based on xpath’s syntax, our xpath would become: //textarea[@id=’sb_form_q’] (see line 14)
Let us enter some text in the search field “rahulshettyacademy” and run the script. Notice below the search field is successfully identified using the xpath and the desired text gets typed in the search field
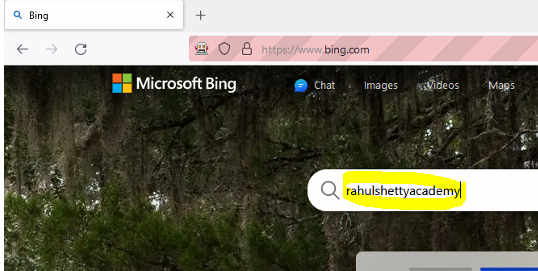
Simplified xpath syntax
We have already seen the xpath syntax: //tagname[@attribute=’value’]
We can simplify this syntax by replacing tagname with star * (star * represents any).
So the simplified xpath syntax becomes //*[@attribute=’value’]
As an example: //*[@id=’sb_form_q’]
So the simplified syntax means that:
find an element on the webpage (irrespective of any tagname) whose attribute ‘id’ has the value ‘sb_form_q’
Let us comment line 14. In line#15, we have used the simplified xpath syntax

Save and execute script, the simplified syntax works just fine
Please remember that we cannot use double quotes within double quotes in xpath syntax. This means that, when we write the xpath syntax, we start by opening and closing the braces with double quotes viz By.xpath(“ “).
Since we have already used one set of double quotes, we cannot write another set of double quotes, below will give syntax error
By.xpath(“//input[@value=“Submit“]”)
To get rid of syntax error, simply convert second set of double quotes with single quote:
By.xpath(“//input[@value=‘Submit‘]”)
xpath regular expression to identify element (‘contains’ keyword)
We can use xpath regular expressions to identify an element. The regular expressions can be used if the value of an attribute changes dynamically.
As an example, the value of ‘id’ attribute might be 397mai543 in one session and 860mai631 in another session. As can be seen, the prefix and suffix is dynamically changing. The static content in both of these values is ‘mai’.
The ‘contains’ keyword can be used to create a regular expression. The syntax would be //tagname[contains(@attribute,’value’)]
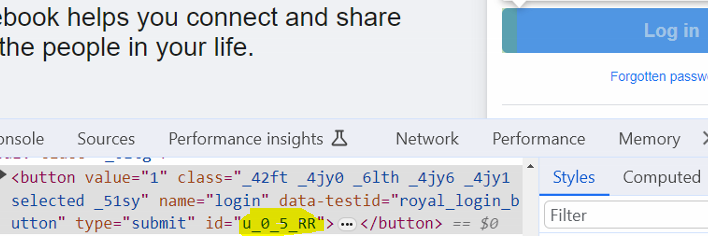
Inspect ‘Log In’ button on the facebook page and notice the value of ‘id’ attribute (u_0_5_gr)
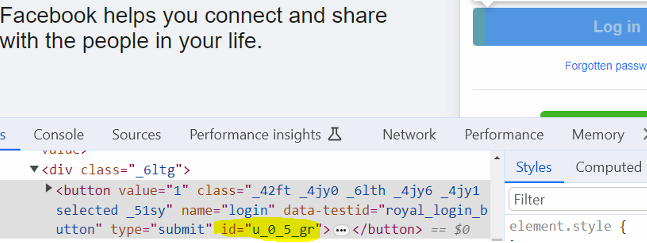
Open another browser session and inspect the ‘Log In’ button once again
Notice above that the value of ‘id’ attribute changes to (u_0_5_RR)
Similarly, the value changes in another session
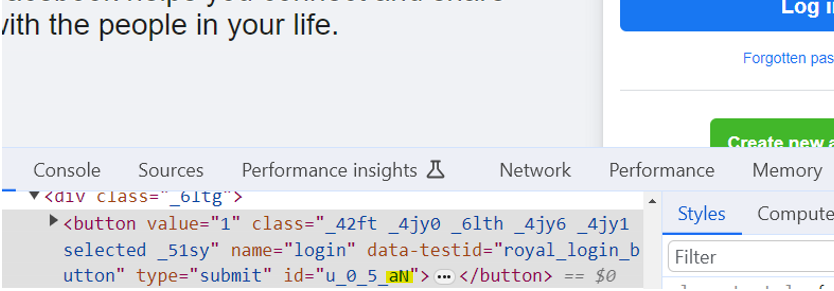
The static part in these three cases is same: u_0_5
We can use the static value of the ‘id’ attribute alongwith the ‘contains’ keyword as shown below
Run, notice that the ‘Log In’ button gets clicked

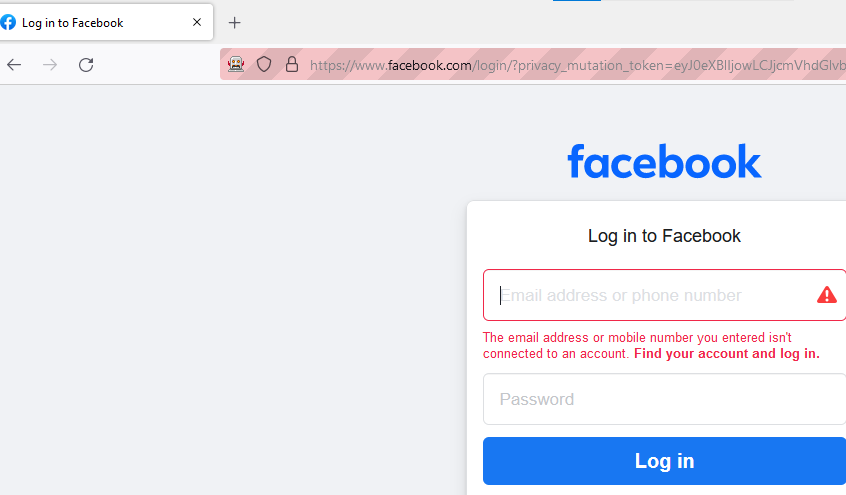
This is how we can use the ‘contains’ keyword to form an xpath regular expression.
If we look at another example (google.com) and inspect the search field, we will notice that the value of ‘data-ved’ attribute keeps changing
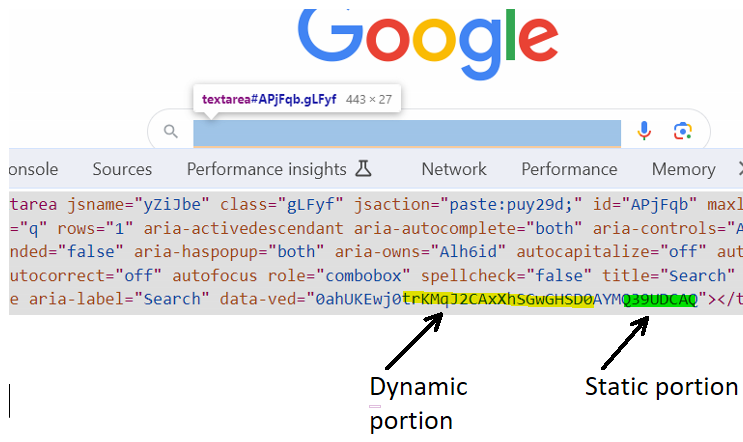
The value contains the static portion CAQ and we can make use of it to identify this search field

Run the script, the search field gets identified and the text gets entered
Parent-child xpath relation
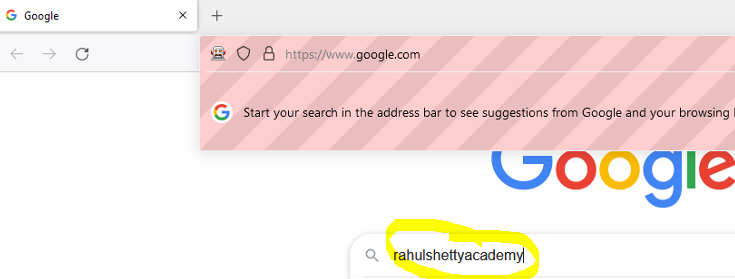
Assume that there is no unique attribute to identify an element on a webpage. Let us assume that the google search field cannot be identified by any unique attribute. In these cases, an xpath is created by using the parent to child relationship. If child does not have a unique attribute, we than look for one of its parent having the unique attribute. We can than write an xpath starting from parent and keep traversing till the child (that has no unique attribute) with the help of tagnames

As seen in the diagram below, the parent <div> tag has a unique ‘class’ attribute. The child tag is <textarea>
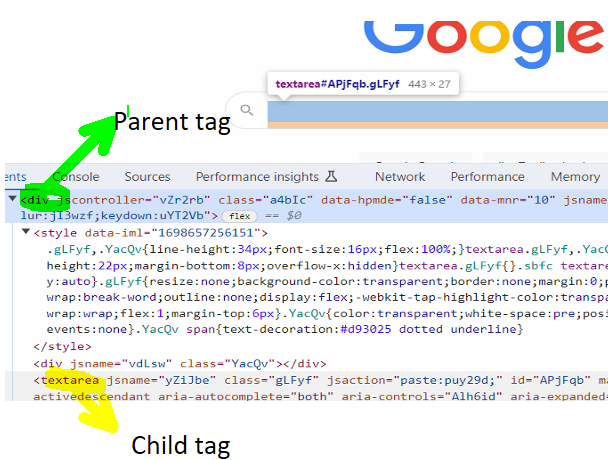
So the parent <div> tag has a unique attribute. Please note that we can keep going one level up till a parent having unique attribute is found.
So, we have found a parent that has ‘div’ tag having ‘class’ value ‘a4bIc’. The parent can be represented by xpath //div[@class=’a4bIc’].
From this parent tag, we will traverse to desired child tag <textarea>
The child tag (here) is the actual search field.
The custom xpath from parent to child path becomes //div[@class=’a4bIc’]/textarea
We can now use this parent-child xpath to enter some value in the text field
Run, ‘rahulshettyacademy’ gets typed in search field

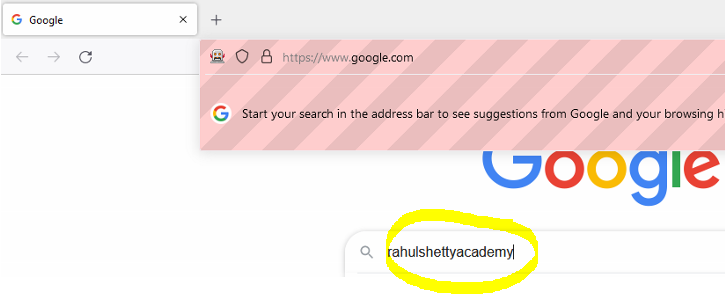
Difference between relative and absolute xpath
In the case of relative xpath, we can jump directly to desired web element. We do not need the help of parent node to find the web element. Relative xpath syntax starts with //.
In the below diagram, the relative xpath //*[@id=’sb_form_q’] can be used to identify the search field. We haven’t taken the help of any parent tag.
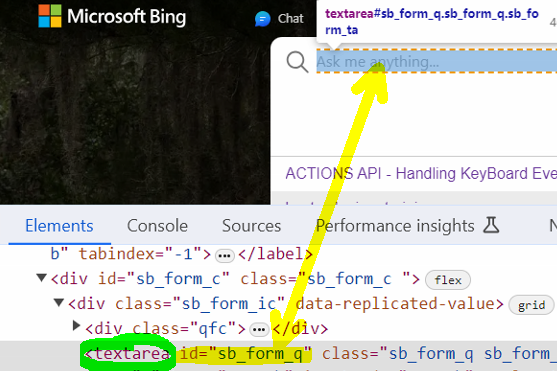
However, for finding the absolute xpath, we have to take the help of all the parent nodes to reach the desired child element. The absolute xpath syntax starts with single slash / and we would be traversing like: /parent/child1/child2/…..
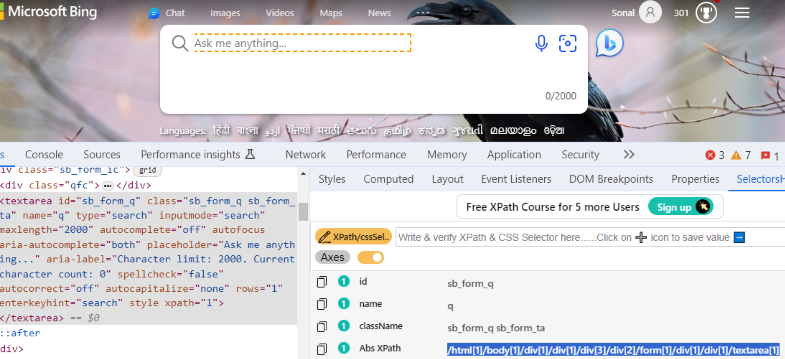
Inspect the search field of www.bing.com
Using the selector’s hub, identify the absolute xpath.
Notice that the absolute xpath starts at /html and ends at /textarea
/html[1]/body[1]/div[1]/div[1]/div[3]/div[2]/form[1]/div[1]/div[1]/textarea[1]
Source code
Thank you!